序言
本篇文章主要是填之前C++11留下的坑以及了解与熟悉线程库,有读者感兴趣之前的内容的话可见「C++进阶之路」专栏中标题为「C++11」的内容,废话不多说,先来概括一下本文的内容,首先我们会从历史的角度分别谈及Linux以及Windows下的线程接口,并从语言的特性简单谈及C++11线程库出现的原因,其次会简单了解并使用关于线程,锁,条件变量的相关接口,简单实现一个自旋锁,然后分析一个常考的线程交替打印的面试题,最后补充一个之前实现shared_ptr中引用计数安全问题和最简单的懒汉模式,并进一步实现C++11版本的线程池。
一、背景
首先,博主在这里贴上一张图,方便读者了解操作系统的整体布局。
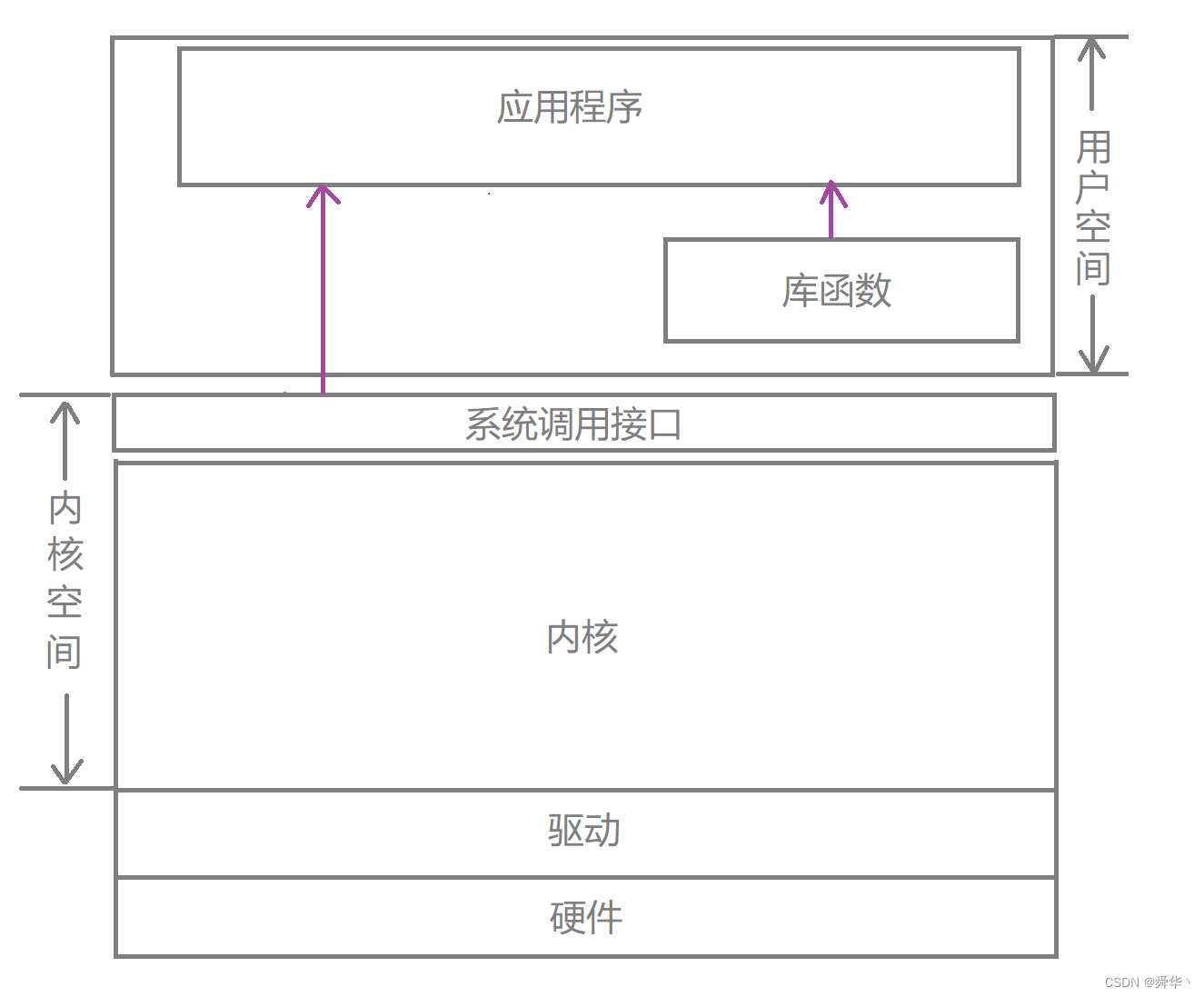
那么,我们所说的线程的接口就在用户空间的库函数中,进一步讲线程库函数的实现在不同的操作系统下实现的标准可能不同。
对于Linux/Unix之类的操作系统中,线程库函数的实现都遵循着POSIX标准,那么我们就可以得出一个结论,即Linux/Unix中关于线程的代码只在具备POSIX标准的操作系统之间具备可移植性。
拓展:
- POSIX,即
PortableOperatingSystemInterface of UNIX,可移植操作系统接口。涉及系统调用和库函数调用。- 电气与电子工程师协会,Institute of Electrical and Electronics Engineers,简称IEEE,是具有较大影响的国际学术组织。
- API ,Application Programming Interface,程序间的接口,即将同类功能的较为复杂的控制逻辑封装成便于接口,供上层用户,更确切的说供程序员快速上手开发。简单举个例子,假如现在你要开发一个程序,首先要想的不是从0到1手搓,而是要用「现成的工具」或者「第三方库」等方式,基本都会提供「封装之后接口」,这些接口就可称为API。
- POSIX是IEEE为要在各种UNIX操作系统上运行的软件而定义的一系列API标准的总称,其正式称呼为IEEE 1003,而国际标准名称为ISO/IEC 9945。
对于Windows的操作系统中,线程库的接口是微软自己开发的一套 Windows API的接口,专门用于开发Windows下的应用程序,那么就很显然,遵循POSIX标准的线程代码在Windows下就跑不起来,那么降低可移植的 “锅” 是不是就可以甩给微软了呢?
- 从历史的角度看,从Win32 API到现在的Windows API来看,微软的设计初衷就与POSIX标准不同。
- 从操作系统的角度看,因为最初设计不同操作系统的理念就不同,所以"不是一家人,不进一家门",微软搞出来的更符合自己的需求。
- 从生态系统的角度看,根据开发者的使用习惯,用惯了Windows的线程接口,可能就用不惯POSIX标准的接口。那么就会更加「闭源」或者就会更加地「独立」和不受外界干扰。
因此,不同操作系统的线程接口的实现标准不同,就会降低代码的在不同平台的可移植性,即不同平台都要使用提供的接口来专门实现,就要写多份功能相同的代码,那么实现的成本就会变高。
那么,C++这门面向对象的高度的封装的语言,就可以进一步通过类似条件编译的形式,对不同平台的接口再进行封装,从而实现「一码多用」的功能,这样就降低了开发人员的工作量以及实现的时间和金钱成本,这是企业和程序员都希望看到的,那么在C++11中线程库的出现就很好地满足了大家的期望,C++这门语言也变得更加成熟,当然如果网络库再弄出来,C++就更完美了。
二、接口使用
1.线程
首先“没有对比就没有伤害”,我们在使用C++11提供的接口之前, 先来简单地使用Windows和Linux下的线程的函数,写一段相同功能的代码。
- Linux
#include<iostream>
#include<pthread.h>
#include<vector>
void* function(void* arg)
{
int* tid = (int*)arg;
printf("I am %d thread\n", *tid);
delete tid;
return nullptr;
}
const int num = 5;
int main()
{
//创建两个线程
std::vector<pthread_t> tids(num);
for(int i = 0; i < num; i++)
{
pthread_create(&tids[i],nullptr,function,new int(i));
}
for(int i = 0; i < num; i++)
{
pthread_join(tids[i],nullptr);
}
return 0;
}
- Windows
#include<iostream>
#include<Windows.h>
DWORD WINAPI ThreadFunction(LPVOID args)
{
int* tid = (int*)args;
printf("I am %d thread\n", *tid);
delete tid;
return 0;
}
/*
参数:void* 的指针,用于「灵活」传参。
返回值:unsigned int,无符号整数。
*/
int main()
{
const int num = 5;
HANDLE threads[num];
for (int i = 0; i < num; i++)
{
threads[i] = CreateThread(nullptr, 0, ThreadFunction, new int(i), 0, nullptr);
/*
参数:
1.属性,一般设置为空,使用默认的即可。
2.新线程堆栈大小,设置为0,表示与原线程使用同样的。
3.线程函数指针,用于运行新线程。
4.线程函数的参数。
5.标志位,0表示使用默认的。
6.输出型参数,用于输出创建线程的id。
返回值:
1.成功,返回线程的操作句柄。
2.失败,返回空指针。
*/
if (threads[i] == nullptr)
{
std::cout << "create thread fail" << std::endl;
return 1;
}
}
//阻塞等待所有的线程。
WaitForMultipleObjects(num, threads, TRUE, INFINITE);
/*
参数:
1.等待的线程数。
2.等待线程的句柄指针。
3.是否等待的所有线程,TRUE——是,FALSE——否。
4.是否阻塞等待,INFITE——是,0——否。
*/
for (int i = 0; i < num; i++)
{
CloseHandle(threads[i]);
/*
参数:线程的操作句柄。
返回值:布尔值,成功,返回true,失败,返回false。
*/
}
return 0;
}
简单地提及一下,博主之前针对Linux下线程写了一篇较为系统的文章——线程,感兴趣可以进去阅读一下,也涉及下面的锁和条件变量,至于Windows下的线程么,大同小异,之后要使用,我们Chat一下样例代码即可快速上手。
先简单的用一下C++11线程库的代码实现上述功能,之后再对接口进行详细的说明。
- C++11
#include<thread>
#include<iostream>
#include<vector>
void function(int i)
{
printf("I am %d thread.\n", i);
}
int main()
{
const int num = 5;
std::vector<std::thread> threads(num);
for (int i = 0; i < num; i++)
{
threads[i] = std::thread(function, i);
}
for (auto& thd : threads)
{
thd.join();
}
return 0;
}
运行结果:
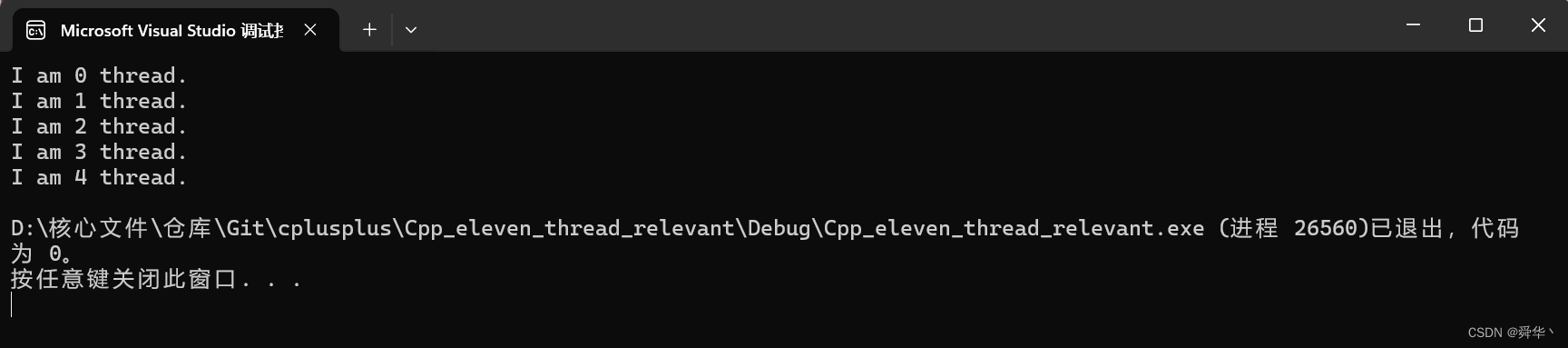
很显然,C++11将线程封装成了类,我们只需要实例化一个对象,然后只需要通过对象暴露出来的外部接口进行操作即可。其次对象放在容器里面进行管理,更为方便。
构造函数与赋值
- 默认构造
thread() noexcept;
//创建一个空线程,这个线程啥也不干。
- 模版构造
template <class Fn, class... Args>
explicit thread (Fn&& fn, Args&&... args);
/*
参数:
1.线程执行对象,可以是函数指针,仿函数,lambda表达式,也可以配合function和bind一起使用。
2.执行对象的参数。
补充知识:作为了解即可
1.explicit,禁止隐式类型转换。
2.template <class Fn, class... Args>,可变参数模版,不断向下层传参数包。
除此之外模版中的右值被称为万能引用,也叫引用折叠。
*/
- 拷贝构造
thread (const thread&) = delete;
thread (thread&& x) noexcept;
/*
说明:
1.左值拷贝被禁止使用了,上述是C++11的语法。
2.右值拷贝可以使用。
*/
- 赋值
thread& operator= (thread&& rhs) noexcept;
thread& operator= (const thread&) = delete;
/*
与拷贝构造同理。
*/
简单谈一下为什么要将左值的线程「拷贝构造/赋值函数」删除,而要将右值的线程「拷贝构造/赋值」函数保留?
-
左值也就是正在运行的线程,你要拷贝这是一件很麻烦的事情,正在的运行线程难道要停下来让你拷贝吗?其次资源也可能存在竞争和混乱的问题,一般访问同一份资源的线程越多,那么就竞争和混乱就越严重,更进一步同步性和互斥性就不太能保证。
-
右值也就是已经「奄奄一息」或者说处于「僵尸」的线程,即已经结束运行,要进一步处理资源的线程,新线程就可以接手其资源,或者这样理解更有意思,这个「奄奄一息」的线程,我们可以理解为「远古始祖的残魂」,「小说的主角」就是「新线程」,最终结果肯定不用多说,始祖夺舍失败,给主角送了一个「开局大礼包」,即资源。
-
一个bug,请看如下代码,你可能觉得没有问题,但是编译器却编译不过。
#include<string>
#include<thread>
void func(std::string& str)
{}
int main()
{
std::string str = "hello world";
std::thread t1(func,str);
//std::thread t1(func,std::ref(str));
t1.join();
return 0;
}
问题的原因可以简单的理解为,传参过程中,参数并不是直接传给func的,而是中间经过了处理,导致最终传给func的是str的拷贝,具有常属性,即使用const类型的引用的参数才可以接收,而权限只能进行平移或者缩小,不能进行扩大,所以这里编译出错。当然也有解决办法,其一就是使用ref说明传入的引用,其二就是不使用引用而是使用指针,其三就是使用lambda表达式。
- 简便的lambda
#include<string>
#include<thread>
#include<iostream>
int main()
{
std::string str = "hello world";
std::thread t1(
[&]
{
str += "!";
std::cout << str << std::endl;
}
);
t1.join();
return 0;
}
关键其实就在于这个捕获列表,贼**好用!
控制线程资源的成员函数
bool joinable() const noexcept;
void join();
void detach();
void swap();
-
joinalbe,即判断一个线程是否在执行相关的对象,即执行线程函数,如果是,则返回true,如果不是,返回false,不是的情况主要有三种,用默认构造函数初始化的线程对象;被当成右值「赋值/拷贝」给了其它线程对象;已经被「join/detach」函数处理过的线程。
-
join,一般是主线程用来阻塞等待创建的线程执行结束的函数,当创建时传入的函数调用完毕返回时,该函数会将线程的状态更改为 non-joinable状态,并将线程的资源安全地进行释放。
-
detach,用来将父线程与子线程进行分离,允许各自独立的执行栈帧,不再互相等待,执行完毕之后会各自安全地释自己的资源。
-
swap,用于交换两个「线程对象」的状态值,值得注意的是「线程」的id值是不会发生变化的,因为线程的id值是在创建时生成的唯一标识符,被用于识别和管理线程。因此注意不要把「线程」和「线程对象」混为一谈,下面博主会给出样例并说明。
-
当一个线程是non-joinable,即调用joinable函数返回false时,才能被「赋值/拷贝」,否则会调用terminate()进行报错。当一个线程是调用joinable函数返回的是true时,才能调用join函数,否则也会调用terminate()进行报错。
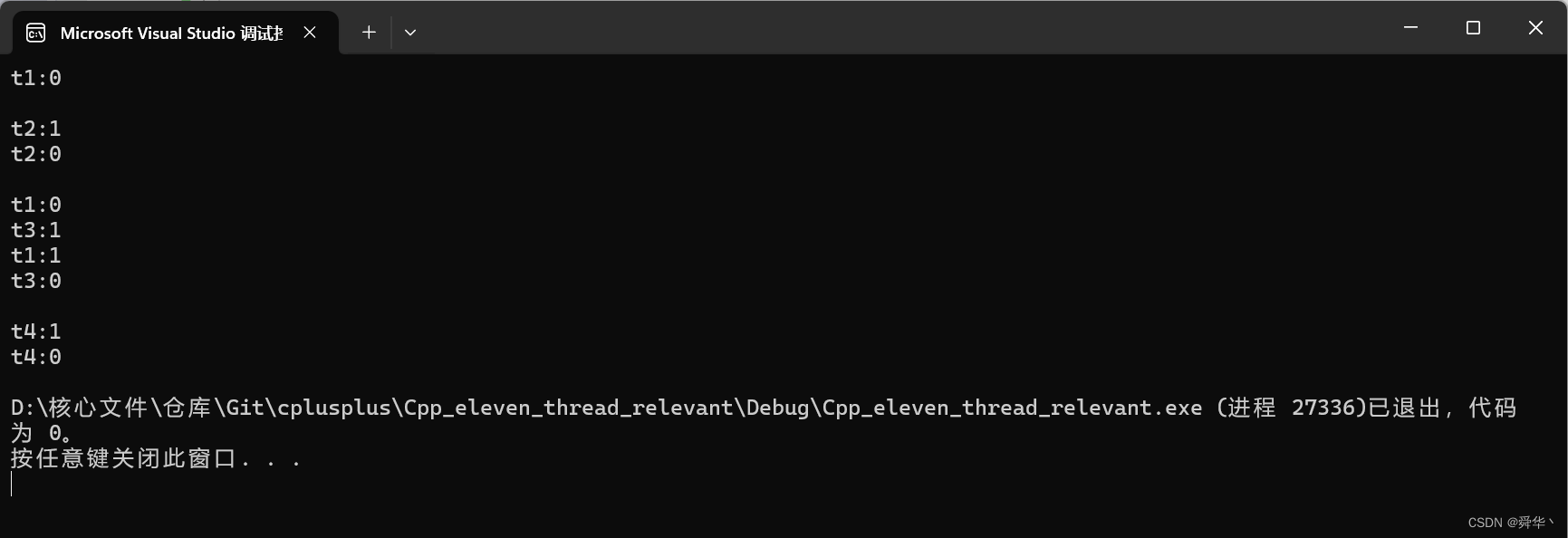
demo1
#include<thread>
#include<iostream>
void func()
{
}
int main()
{
std::thread t1;
std::thread t2(func);
//1.空线程——t1
std::cout << "t1:" << t1.joinable() << std::endl << std::endl;
std::cout << "t2:" << t2.joinable() << std::endl;
t2.join();
//运行时出异常
//t1.join();
//2.join之后的线程——t2
std::cout << "t2:" << t2.joinable() << std::endl << std::endl;
//3.拷贝/赋值之后的线程——t1,t3
std::thread t3(func);
std::cout << "t1:" << t1.joinable() << std::endl;
std::cout << "t3:" << t3.joinable() << std::endl;
t1 = move(t3);//move将左值变为右值。
std::cout << "t1:" << t1.joinable() << std::endl;
std::cout << "t3:" << t3.joinable() << std::endl << std::endl;
t1.join();
//4.detach的线程
std::thread t4(func);
std::cout << "t4:" << t4.joinable() << std::endl;
t4.detach();
std::cout << "t4:" << t4.joinable() << std::endl;
return 0;
}
运行结果:
demo2:
#include <iostream>
#include <thread>
#include <Windows.h>
void func1()
{
std::cout << "func1:" << std::this_thread::get_id() << std::endl;
Sleep(1000);//休眠一秒。
std::cout << "func1:" << std::this_thread::get_id() << std::endl;
}
void func2()
{
std::cout << "func2:" << std::this_thread::get_id() << std::endl;
Sleep(1100);//休眠一秒。
std::cout << "func2:" << std::this_thread::get_id() << std::endl;
}
int main()
{
std::thread t1(func1);
std::thread t2(func2);
std::cout <<"t1:" << t1.get_id() << std::endl;
std::cout <<"t2:" << t2.get_id() << std::endl;
Sleep(500);//休眠0.5秒。
t1.swap(t2);
std::cout <<"t1:" << t1.get_id() << std::endl;
std::cout <<"t2:" << t2.get_id() << std::endl;
t1.join();
t2.join();
}
- 休眠的作用,就是能够大概率看到「管理线程信息的对象」和「线程」在swap前和swap后的id值。
- 线程对象,可以理解为是管线程的「私人教练」,而线程就为「你这个人」本身,那么教练换了,不代表你人变了,只是换了另一个教练调教你而已,因此上述代码,即可理解为两个人,交换了双方的「私人教练」,因此教练调教的对象信息发生了变化,即id值变化,而正在被指导的你是没有变化的,所以你的id值是没有变化的。
因此,实验的结果为:
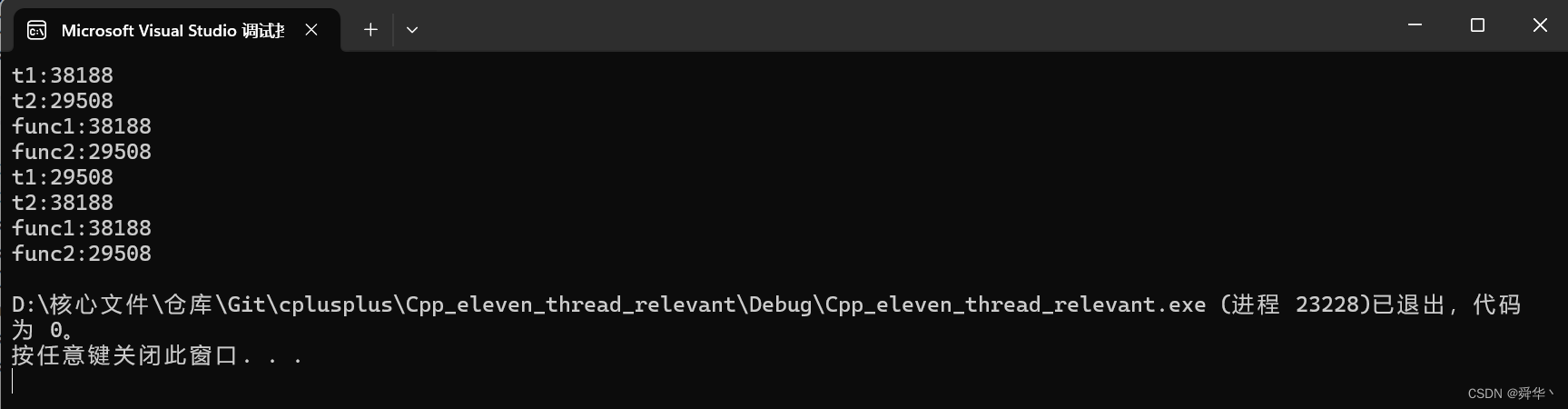
说明:打印会出现错乱的现象,这是很正常的,弄懂了下文锁相关的「临界资源」这个概念,便一目了然。
可全局调用的接口
当我们获取线程的id值时,可以通过线程成员函数中的get_id在父线程中获取并打印,但要是在线程执行的栈中获取get_id值就需要命名空间this_thread中的全局接口了。
demo1
#include <iostream>
#include <thread>
//主线程id
std::thread::id main_thread_id = std::this_thread::get_id();
//用于判断是否为主线程
void is_main_thread()
{
if (main_thread_id == std::this_thread::get_id())
{
std::cout << "This is the main thread." << std::endl;
}
else
{
std::cout << "This is not the main thread." << std::endl;
}
}
int main()
{
is_main_thread();
std::thread t(is_main_thread);
t.join();
}
打印结果:
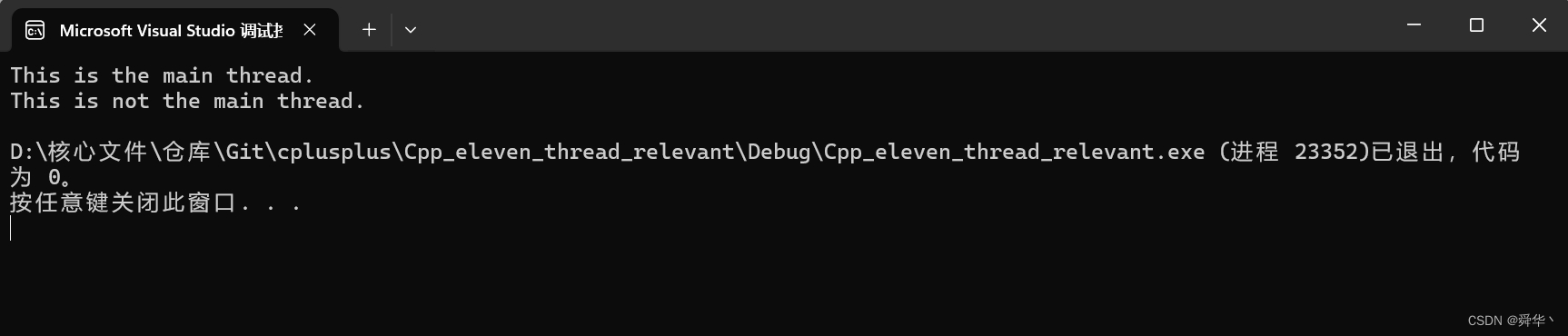
说明:打印会出现错乱,但是打印出this is the main thread的是主线程执行的结果。
当我们不想让当前线程,在CPU上消耗时间片的同时,执行单一重复且无效的动作时,我们可以让当前线程「歇一会儿」再继续执行,可以让其它线程做一些「有用功」,同时「单一重复且无效」往往指的是资源正被其它线程占用,你本就该歇一会,让占用资源的线程赶紧把任务完成,将资源释放,好让当前线程在之后获取。这种可以提高效率的行为,可以使用yield函数进行实现。
- yield,用于非阻塞地剥离在CPU上运行的线程,等待下一轮重新被调用,可以提高CPU的效率,减少资源的浪费。会在实现自旋锁的过程中,涉及到此接口,此处只进行简要的说明。
当我们想让当前的线程休眠一会儿,或者休眠到指定时间时,就涉及到与线程sleep相关的休眠函数,但在这之前,我们先来理解「休眠」,以及与进程和线程之间的关系。
首先休眠状态,指的是当满足一定的条件,然后调用休眠函数,让进程或者线程进入休眠,然后休眠完毕,被唤醒这一过程。线程的休眠相比于进程的休眠,简单地从资源的角度对比,进程的多个线程共享同一份进程资源,那么线程的休眠就更加地「轻量化」。
- sleep_for,将线程等待一段固定的时间,比如等待两分钟。
- sleep_until,让线程等待到某一特定的时间,比如等待到十点十分。
#include <iostream>
#include <thread>
#include<chrono>
#include<ratio>
#include<ctime>
void fun1()
{
std::cout << "sleep two seconds" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
//根据不同的时间单位,休眠指定的时间。
/*
std::chrono::minutes(1);
std::chrono::hours(1);
*/
}
void fun2()
{
std::chrono::duration<int, std::ratio<10>> ten_seconds(1);
//duration,一个表明时间单位的类,ration<n>,设置的基本单位为秒,即n秒为一个单位。
//构造初始化给的参数即为单位的个数。
auto now_time = std::chrono::system_clock::now();
//返回的是一个 time_point的类型的,表示具体的时间点。
auto wait_time = now_time + ten_seconds;
//重载operator +,可得到10秒之后具体的时间点。
auto now_data = std::chrono::system_clock::to_time_t(now_time);
//将time_point类型转换为time_tl类型的。
auto aft_data = std::chrono::system_clock::to_time_t(wait_time);
//同上。
std::cout << "Current Time:" << std::ctime(&now_data);
//将时间用字符串具体地进行表示。
std::this_thread::sleep_until(wait_time); //传入参数为time_point类型的。
std::cout << "Wait Time:" << std::ctime(&aft_data);
}
int main()
{
std::thread t1(fun1);
std::thread t2(fun2);
t1.join();
t2.join();
return 0;
}
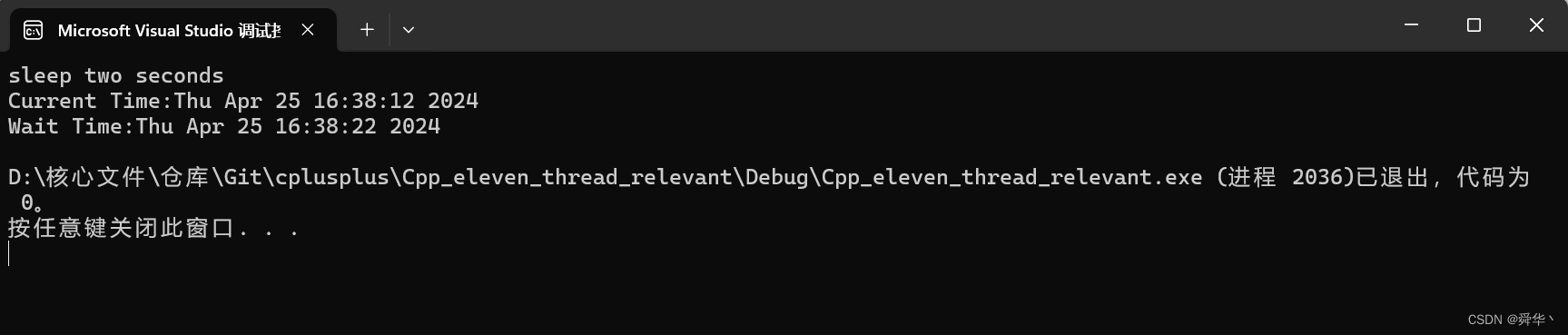
说明:t1管理的线程休眠固定的时间段,t2管理的线程休眠到指定的时间点,更详细的接口使用,详见官方文档
运行结果:
2.锁
在谈论锁之前,就不得不提及「原子」这个概念,意思是CPU执行操作的最小单元,简单理解为「干一碗饭」,要么就不干,要么就把这一碗饭干完,不能干一半剩下不管。一般来说,将一条汇编指令看做是原子的,当然也有不是原子的汇编指令,具体涉及RISC——精简指令集,以及CISC——复杂指令集,可查阅资料进行进一步的了解。
那么加入了多线程这个变量,就出现了「共享资源」这个概念,即多个线程访问同一份资源,就出现了「数据不一致」的问题,我们用如下代码先来观察现象:
#include<thread>
#include<iostream>
int main()
{
int x = 0;
auto func = [&]()
{
for (int i = 0; i < 10000; i++)
{
x++;
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
请读者用直观猜测这里应该打印的结果为多少,再思考几秒。然后将由我来告诉你答案,多运行几遍此代码平均下来要比20000要小,甚至说要小很多,下面是运行一次的结果:

原因图解:
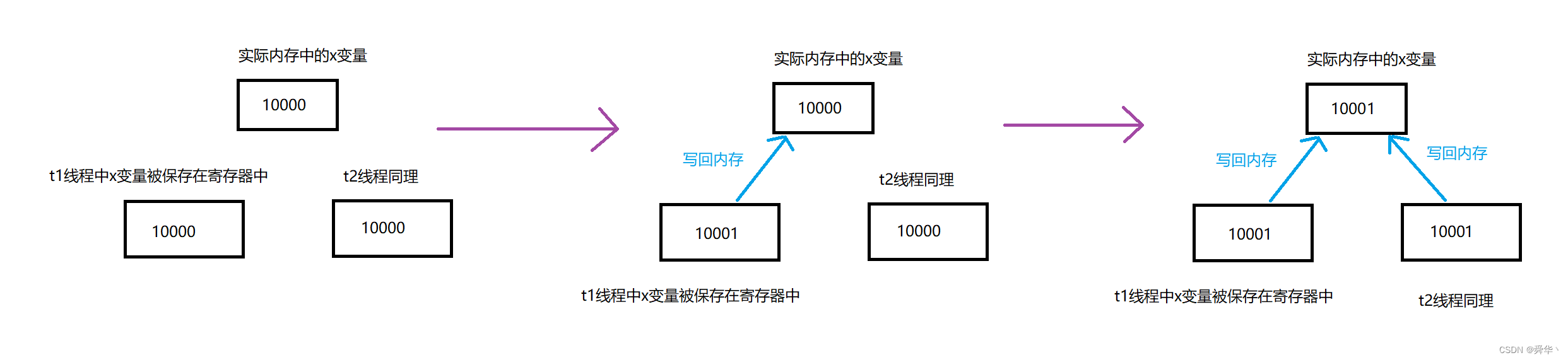
核心原因就在于在有「一个线程在更新变量之后,另一个线程的寄存器中的值没有被更新」。进而导致「两次加加只进行了一次有效动作」。那么这个x我们就称之为共享资源,这个问题就被称为数据不一致的问题。
最终就迎来了锁这一解决办法,即「一个线程在更新变量时,其它线程不得访问这个变量」,也就是「加锁和解锁」。至于锁的原理,上文中提及的关于线程的文章进行了详细的讨论,本篇文章就不再进行赘述了。
至于锁接口的实现,在Linux和Windows下也是各不相同,作者分别贴了不同版本的相同功能的代码,感兴趣的可以复制去不同平台多运行几遍,看是否还会出现「资源不一致」的问题。
- Linux
#include<iostream>
#include<vector>
#include<thread>
#include<pthread.h>
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
int main()
{
int x = 0;
auto func = [&]()
{
for(int i = 0; i < 10000; i++)
{
pthread_mutex_lock(&lock);
x++;
pthread_mutex_lock(&lock);
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
- Windows
#include<iostream>
#include<Windows.h>
#include<thread>
//或者使用锁
CRITICAL_SECTION cs;
void InitLock()
{
// 初始化临界区
InitializeCriticalSection(&cs);
}
void Lock()
{
// 进入临界区,如果已经被锁定,则会阻塞线程直到锁被释放
EnterCriticalSection(&cs);
}
void Unlock()
{
// 退出临界区,释放锁
LeaveCriticalSection(&cs);
}
void CleanupLock()
{
// 销毁临界区
DeleteCriticalSection(&cs);
}
int main()
{
//初始化临界区。
InitLock();
int x = 0;
auto func = [&]()
{
for(int i = 0; i < 10000; i++)
{
Lock();
x++;
Unlock();
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
//释放临界区。
CleanupLock();
std::cout << x << std::endl;
return 0;
}
此时,我们再来看一下C++11线程库的使用锁的代码,相信会有不同的感受。
- lock(阻塞式)
#include<thread>
#include<mutex>
#include<iostream>
int main()
{
std::mutex mtx;
int x = 0;
auto func = [&]()
{
for (int i = 0; i < 10000; i++)
{
mtx.lock();
x++;
mtx.unlock();
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
- trylock(非阻塞式)
#include<thread>
#include<mutex>
#include<iostream>
int main()
{
std::mutex mtx;
int x = 0;
auto func = [&]()
{
for (int i = 0; i < 10000; i++)
{
while (!mtx.try_lock())
{
std::this_thread::yield();//让一下时间片,提高效率。
}
x++;
mtx.unlock();
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
除此之外,还有其它类型的锁,使用也很简单,这里提及一下,有兴趣详见官网文档。
- recursive_mutex,即递归锁,线程函数也可能进行递归,那么临界资源的申请就可能会重复上锁,如果不加以控制,那么就会出现死锁的问题,那么递归锁引入了一个「所有权级别」的概念,简单的理解为递归可以加锁,且加锁的次数越多,级别越深。且当解锁的次数等于加锁的次数时,才算真正的解锁。以上都是对同一把锁进行加锁和解锁。
- timed_mutex,相比于mutex的接口,多了
try_lock_until和try_lock_for两个可以设置超时「时间点/时间段」的函数,即在指定的一段「时间段/时间点」内进行申请,申请成功返回false,失败返回true。
为了使用方便,C++11还引入了lock_guard 和 unique_lock两种具有RAII思想的锁。
- lock_guard,实现起来很简单,如下是一种可能的简单实现。
#include<mutex>
template<class mutex_type>
struct lock_guard
{
lock_guard(std::mutex& mtx)
:_mtx(mtx)
{
_mtx.lock();
}
~lock_guard()
{
_mtx.unlock();
}
std::mutex_type& _mtx;
};
只需将锁交给此对象,使用构造和析构的自动化,自动的完成加锁和解锁,下面是一段简单的使用代码。
#include<thread>
#include<iostream>
int main()
{
std::mutex mtx;
int x = 0;
auto func = [&]
{
for (int i = 0; i < 10000; i++)
{
{
lock_guard<std::mutex> lg(mtx);
x++;
}
//如果有其它变量,比如线程里面的局部变量,我们不想锁住,
//就可以使用{}来限定锁的生命周期,变向的完成解锁功能。
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
- unique_lock,使用方法与lock_guard类似,不过特别的是,其通常配合着下文提及的「条件变量」一块使用。
原子操作
在谈原子操作之前,我们先来讨论两个概念——「临界区」以及「无锁编程」。临界区,简而言之就是涉及到临界资源的代码块,也就是需要加锁和解锁的代码块,那么当临界区过短时,加锁和解锁便成为了一种阻挡效率的负担,有点「杀鸡焉用宰牛刀」的感觉。此时就会产生「无锁编程」的概念,即不用锁就可解决资源不一致的问题,这就是「朝向坤坤的小刀」。
那么C++11库里面提供了类似atomic模版类,主要涉及atomic类以及atomic_flag类,先简单使用前者,后者在下面将用于自旋锁的实现。
那么对之前两个线程同时对一个变量加加一万次的操作,就可以写为:
#include <iostream>
#include <atomic>
#include<thread>
int main()
{
std::atomic<int> x = 0;
auto func = [&]()
{
for (int i = 0; i < 10000; i++)
{
x++;
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
补充:
- atomic类一般只能用于内置类型,或者满足可直接完成内存复制的,具有拷贝构造,移动构造,拷贝赋值,移动赋值的自定义类型。
- atomic类中具有运算功能的主要有fetch系列以及operator系列,可以支持基本的运算场景。特殊的operator T()是隐式类型转换。
- atomic类中还有is_lock_free,检测是否支持无锁操作;store和load分别完成值的赋值和获取工作,exchage则可同时完成赋值和获取。
原理:
简单的谈一下底层,当两个线程同时对一个变量进行更新操作时,肯定是一个线程的寄存器先完成对在内存的变量的赋值,且此时另一个线程不能再赋值,应该先检查值是否「更新了」,如果更新了,就更新另一个线程中寄存器的值,再执行一遍更新操作之后,如果更新之后,内存的值没有进行更新,那么就完成对内存的赋值。大体上类似do while循环的感觉。
接口说明:
template <class T>
bool atomic_compare_exchange_weak (atomic<T>* obj, T* expected, T val) noexcept;
/*
参数:
1.atomic<T>类的指针,即指向变量的内存。
2.T类型的指针,即变量的内存的值可以被赋值的值。前两个参数用于检测值是否被其它线程修改过。
3.要将obj指向变量修改的值。
*/
demo
#include <iostream>
#include <atomic>
#include<thread>
int main()
{
std::atomic<int> x = 0;
int sz = 10000;
auto func = [&]()
{
for (int i = 0; i < sz; i++)
{
int old_val;
int new_val;
do
{
old_val = x;
new_val = old_val + 1;
//如果比较失败之后,会更新old_val
} while (!std::atomic_compare_exchange_weak(&x, &old_val, new_val));
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
着重强调,这里只是实现了一个简单的无锁操作,现实中的如果要进行无锁编程,涉及到的细节之多,简直令人发指,因此在功力不足之前,以了解和熟悉为主,一般能用锁就用锁。如果头铁硬要实现无锁编程,可以参考网上的代码和文章,此处简要贴上一篇陈皓大佬写的一篇关于无锁编程的文章,方便读者进行拓展——无锁队列的实现
自旋锁
接下来,根据atomic_flag类简单地实现一个spin_lock,即自旋锁。
思路:
- 首先,设置一个atomic_flag的类的成员变量,并使用
ATOMIC_FLAG_INIT进行初始化。 - 其次,锁是不能发生拷贝赋值的,因此要使用
delete将相关的进行禁用。 - 最后,加锁使用
test_and_set不断地设置,如果申请失败使用yield分出时间片;解锁使用clear接口即可。
实现:
#include<atomic>
struct spin_lock
{
//使用默认的构造函数
spin_lock() = default;
//拷贝和赋值进行删除
spin_lock(const spin_lock& lock) = delete;
spin_lock& operator = (const spin_lock& lock) = delete;
//加锁
void lock()
{
while (flag.test_and_set(std::memory_order_acquire))
{
std::this_thread::yield();//申请失败,让出时间片。
}
}
void unlock()
{
flag.clear(std::memory_order_release);
}
private:
std::atomic_flag flag = ATOMIC_FLAG_INIT;
};
测试代码:
#include<iostream>
#include<thread>
int main()
{
spin_lock slk;
int x = 0;
auto func = [&]()
{
for (int i = 0; i < 10000; i++)
{
slk.lock();
x++;
slk.unlock();
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
std::cout << x << std::endl;
return 0;
}
说明:
- memory_order_acquire, 可以确保在读取共享数据时,不会读取到尚未完成的写操作的结果,从而避免出现数据竞争和不一致的情况。
- memory_order_release, 用于指定对共享数据的写操作的内存顺序,确保写操作正常。
3.条件变量
为了方便读者理解,这里举个简单的例子,假如在食堂买饭时,大家都不在在窗口后面进行「排队」,而是「一窝蜂」的围在窗口嚷嚷,此时就会处于一片「混乱」,那么排队就可以避免这种混乱,且可以保证一定的「公平性」。简而言之,条件变量就是用来保证同步性,让大家排好队,也可以理解为「队列」的数据结构,具备「先进先出」的特性。
同样的先来看看Linux和Windows的条件变量的使用:
- Linux
#include<iostream>
#include<vector>
#include<pthread.h>
#include<unistd.h>
using namespace std;
//设置一个静态的锁
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
//设置一个条件变量
pthread_cond_t con = PTHREAD_COND_INITIALIZER;
//简单的对锁进行封装。
struct mutex
{
mutex(pthread_mutex_t *lock)
:_mutex(lock)
{
pthread_mutex_lock(_mutex);
}
~mutex()
{
pthread_mutex_unlock(_mutex);
}
pthread_mutex_t* _mutex;
};
void* Runroutinue(void* arg)
{
//{}可以使临界区可视化,并在使用RAII的锁中有奇效。
{
mutex mu(&lock);//加锁
//这一步的作用葫芦娃救爷爷,一个一个来,都进来先去排队。
cout << "tid:" << pthread_self() << endl;
pthread_cond_wait(&con,&lock);
cout << "------------------------" << endl;
//排队,就可理解为陷入阻塞状态,等待被唤醒,此时锁释放,被其它线程获取。
cout << "tid:" << pthread_self() << endl;
}
return nullptr;
}
const int pthread_num = 5;
vector<pthread_t> tids;
void create()
{
for(uint64_t i = 0; i < pthread_num; i++)
{
pthread_t tid;
pthread_create(&tid,nullptr,Runroutinue,nullptr);
tids.push_back(tid);
}
}
void joins()
{
for(int i = 0; i < pthread_num; i++)
{
pthread_join(tids[i],nullptr);
}
}
void ctrl()
{
//一次唤醒一个线程
int end = pthread_num;
while(end--)
{
pthread_cond_signal(&con);
//唤醒一个线程之后,会让其重新拥有锁。
sleep(1);
}
}
int main()
{
create();
sleep(1);
ctrl();
joins();
return 0;
}
- Windows
#include<iostream>
#include<Windows.h>
#include<thread>
//锁
CRITICAL_SECTION cs;
//条件变量
CONDITION_VARIABLE cv;
//线程数量
const int thread_num = 5;
//线程句柄
HANDLE threads[thread_num];
void InitLock()
{
// 初始化临界区
InitializeCriticalSection(&cs);
}
void Lock()
{
// 进入临界区,如果已经被锁定,则会阻塞线程直到锁被释放
EnterCriticalSection(&cs);
}
void Unlock()
{
// 退出临界区,释放锁
LeaveCriticalSection(&cs);
}
void CleanupLock()
{
// 销毁临界区
DeleteCriticalSection(&cs);
}
DWORD WINAPI ThreadFunction(LPVOID args)
{
{
Lock();
std::cout << "tid :" << GetCurrentThreadId() << std::endl;
//让线程去条件变量下等待,即进队列排队。
SleepConditionVariableCS(&cv, &cs, INFINITE);
std::cout << "-------- wake begin -----------" << std::endl;
std::cout << "tid :" << GetCurrentThreadId() << std::endl;
std::cout << "-------- wake done -----------" << std::endl;
Unlock();
}
return 0;
}
void ctrl()
{
int cnt = thread_num;
while (cnt--)
{
//唤醒条件变量下的线程。
WakeConditionVariable(&cv);
Sleep(1000);//休眠一秒大概率保证唤醒的线程已经获取到锁了。
}
}
void create()
{
for (int i = 0; i < thread_num; i++)
{
threads[i] = CreateThread(nullptr, 0, ThreadFunction, nullptr, 0, nullptr);
}
}
void joins()
{
for (int i = 0; i < thread_num; i++)
{
WaitForSingleObject(threads[i], INFINITE);
}
/*
WaitForMultipleObjects(thread_num, threads, TRUE, INFINITE);
一次等所有的线程也行。
*/
}
int main()
{
InitLock();
create(); //创建线程
Sleep(1000);//休眠一秒
ctrl(); //唤醒线程
joins(); //处理线程
CleanupLock();
return 0;
}
再来体验一下C++11,写同类功能的代码。
#include<iostream>
#include<thread>
#include<mutex>
#include<vector>
#include<chrono>
std::mutex mtx;
std::condition_variable cv;
const int thread_num = 5;
std::vector<std::thread> ths(thread_num);
void func()
{
{
std::unique_lock<std::mutex> lg(mtx);
std::cout << "tid:" << std::this_thread::get_id() << std::endl;
//让线程进入条件变量下等待。
cv.wait(lg);
std::cout << "------------- wake begin ----------------" << std::endl;
std::cout << "tid:" << std::this_thread::get_id() << std::endl;
std::cout << "------------- wake end ----------------" << std::endl;
}
}
void create()
{
for (auto& th : ths)
{
th = std::thread(func);
}
}
void ctrl()
{
int cnt = thread_num;
while (cnt--)
{
cv.notify_one();
std::this_thread::sleep_for(std::chrono::seconds(1));
//保证线程被唤醒的一个抢到锁。
}
}
void joins()
{
for (auto& th : ths)
{
th.join();
}
}
int main()
{
create(); //创建线程
std::this_thread::sleep_for(std::chrono::seconds(1));//休眠一秒确保所有线程都进条件变量下等待
ctrl(); //唤醒线程
joins(); //处理线程
return 0;
}
运行结果:
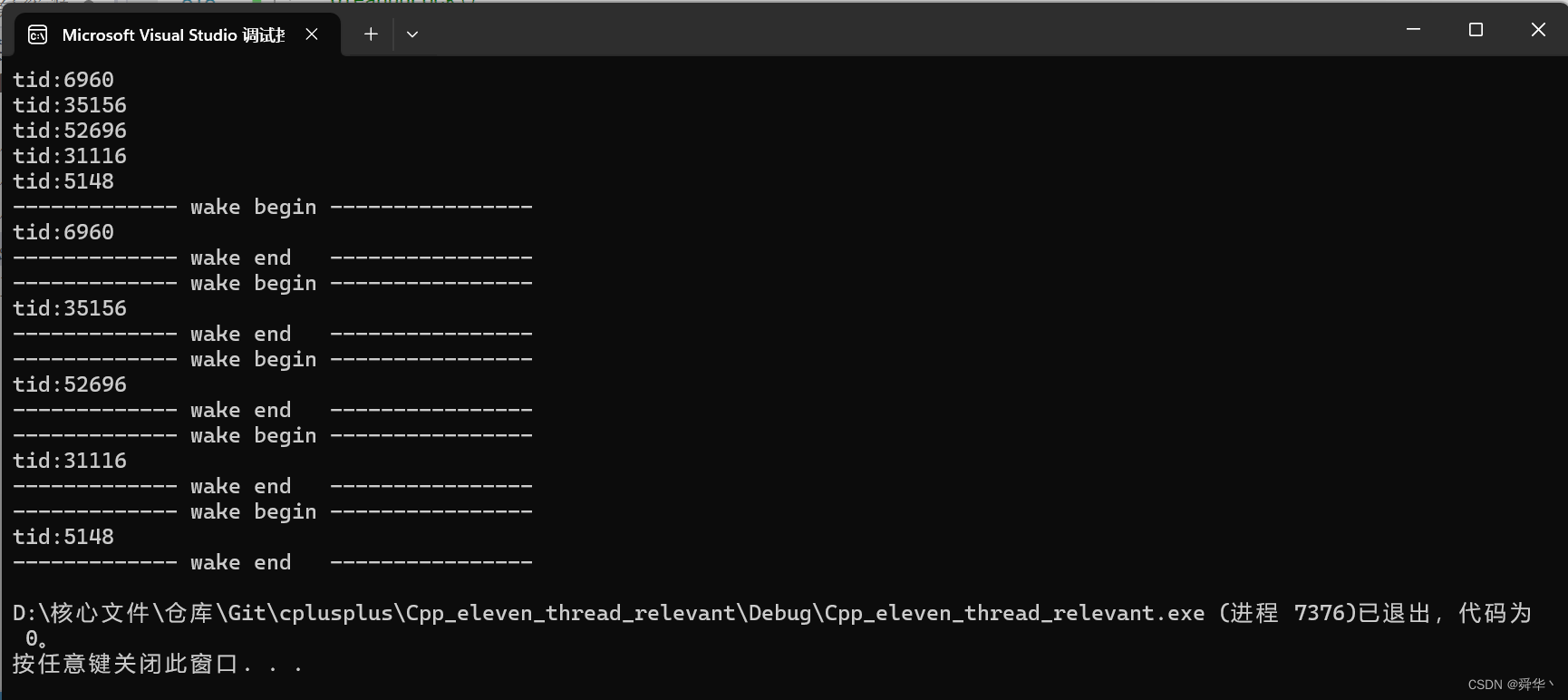
- 可以从结果中观察出,「先进先出」的特点,即先进入条件变量下的线程,先被唤醒,保持队列的属性。
- 其次值得注意的是,再进入条件变量下进行等待时是要抱着锁等待的,「抱着锁」进去是为了「将锁释放」,避免陷入死锁问题。
notify_one,是一次唤醒一个线程,当条件变量下的线程为空时,调用此函数不会报错,只是啥也不干。因此创建线程之后休眠一秒可以大概率保证所有线程都进入条件变量下等待,以确保每次唤醒时做的都是有用功,其次库里还有一个notify_all唤醒所有线程,使用方法大同小异,不过一般不会使用此函数,因为会出现「惊群效应」。wait,让线程陷入等待被唤醒的状态,库里面还有wait_for以及wait_until类似的接口,即休眠「一段时间/到指定时间点」再去条件变量下等待,通常要搭配cv_status::timeout进行使用。- 提及一下另一个类型的条件变量
condition_variable_any,此类型的变量可以更加灵活的与锁搭配进行使用,里面的成员函数基本上都是模版类型的,而此处所提及的只能与unique_lock搭配着进行使用。
4.线程安全
请读者来思考一道关于线程条件变量的面试题,学到就是赚到,假如给你两个线程,分别为「线程A」和「线程B」,和「一个被初始化为1的整形变量」,此时要让「线程A」打印奇数,每次打印完之后通知「线程B」打印偶数,如此交替进行,打印200以内的整数。这道题很考验对线程安全的细节方面的理解。
实现:
#include<iostream>
#include<mutex>
#include<thread>
#include<condition_variable>
int main()
{
bool flag = false;
int n = 1;
std::condition_variable cv;
std::mutex mtx;
//t1线程打印奇数,t2线程打印偶数
std::thread t1([&]()
{
for (int j = 1; j <= 100; j++)
{
std::unique_lock<std::mutex> lg(mtx);
while (flag)
cv.wait(lg);
std::cout << "t1:" << n++ << std::endl;
flag = true;
cv.notify_one();
}
}
);
std::thread t2([&]()
{
for (int j = 1; j <= 100; j++)
{
std::unique_lock<std::mutex> lg(mtx);
while (!flag)
cv.wait(lg);
std::cout << "t2:" << n++ << std::endl;
flag = false;
cv.notify_one();
}
}
);
t1.join();
t2.join();
return 0;
}
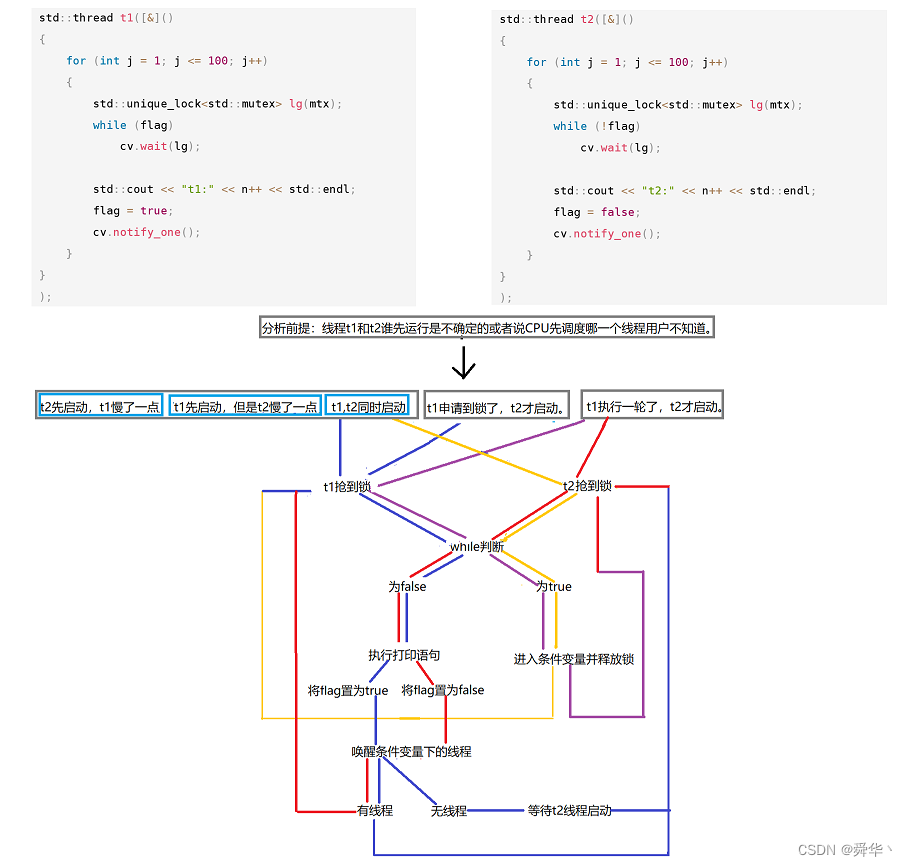
-
图解:
-
点睛之笔:打印之后的flag更新,既能防止自己下一次重新打印,也能让放开另一个线程进行打印。
-
拓展:如果是三个线程进行交替打印呢?欢迎在评论区进行讨论。
shared_ptr引用计数
在之前实现过智能指针,其中就包括shared_ptr,这里直接接着上文接着讲,不清楚或者不太了解的可见C++11(中),详见目录智能指针部分。那么当多线程访问这个引用计数资源时,是否会发生资源不一致的问题呢?
直接上代码进行测试:
#include<thread>
namespace MY_SMART_PTR
{
template<class T>
class shared_ptr
{
public:
shared_ptr(T* ptr = nullptr)
:_ptr(ptr)
, _pcount(new int(1))
{}
~shared_ptr()
{
if (--(*_pcount) == 0)
{
delete _ptr;
delete _pcount;
}
}
T& operator *()
{
return *_ptr;
}
T* operator ->()
{
return _ptr;
}
shared_ptr(shared_ptr<T>& ptr)
:_ptr(ptr._ptr)
, _pcount(ptr._pcount)
{
(*_pcount)++;
}
shared_ptr<T>& operator = (shared_ptr<T>& ptr)
{
//判断是否相等,包括资源指向空的情况
if (ptr._pcount == _pcount)
return *this;
//*this的_pcount的内容进行减减,判断是否为0
if (--(*_pcount) == 0)
{
delete _ptr;
delete _pcount;
}
//对ptr指向的pcount加加
_ptr = ptr._ptr;
_pcount = ptr._pcount;
++(*_pcount);
return *this;
}
T* get()const
{
return _ptr;
}
private:
T* _ptr = nullptr;
int* _pcount = nullptr;
};
}
int main()
{
MY_SMART_PTR::shared_ptr<int> ptr(new int(1));
auto func = [&] {
for (int i = 0; i < 1000; i++)
{
MY_SMART_PTR::shared_ptr<int> tmp = ptr;
}
};
std::thread t1(func);
std::thread t2(func);
t1.join();
t2.join();
return 0;
}
运行结果:
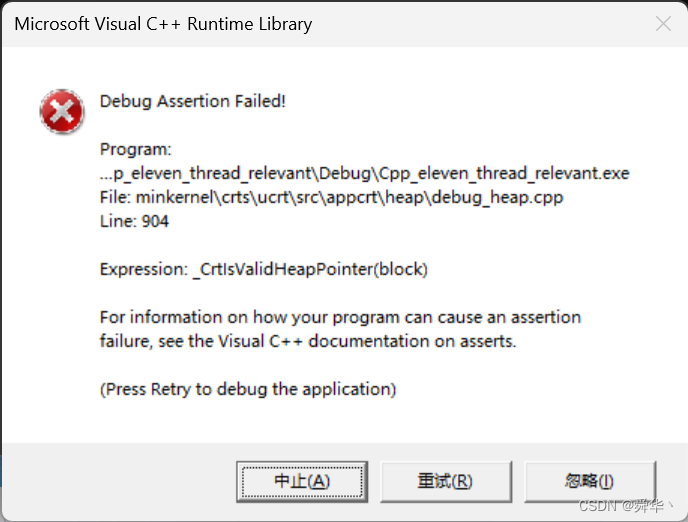
很显然,出异常了,这个结果多运行几遍代码很容易就能看到,这很明显是因为引用计数是共享资源,而多线程访问共享资源就会出现资源不一致的问题,那么就可能多次delete,进而会出异常。解决方法也很简单,要么加锁,不过因为只是对一个int变量进行操作,因此可以直接使用atomic<int>类型的,这样代码改动的地方就很少了。
更新代码如下:
namespace MY_SMART_PTR
{
template<class T>
class shared_ptr
{
public:
shared_ptr(T* rsptr = nullptr)
:_rsptr(rsptr), _pcount(new std::atomic<int>(1))
{}
//拷贝构造
shared_ptr(shared_ptr<T>& copy)
:_rsptr(copy._rsptr)
{
_pcount = copy._pcount;
++(*_pcount);
}
赋值
shared_ptr<T>& operator =(shared_ptr<T>& copy)
{
//第二种判断:
if (_pcount == copy._pcount)
{
return *this;
}
//先判断当前的引用计数
if (_pcount && --(*_pcount) == 0)
{
delete _rsptr;
delete _pcount;
_rsptr = _pcount = nullptr;
}
//再将赋值
_rsptr = copy._rsptr;
_pcount = copy._pcount;
//在对引用计数加加
++(*_pcount);
return *this;
}
析构
~shared_ptr()
{
if (_pcount && --(*_pcount) == 0)
{
//先将资源进行处理
_del(_rsptr);
delete _pcount;
_pcount = nullptr;
_rsptr = nullptr;
std::cout << "~shared_ptr()" << std::endl;
return;
}
}
//运算符重载
T& operator*()
{
return *_rsptr;
}
T* operator->()
{
return _rsptr;
}
private:
T* _rsptr;
//一个线程安全的问题。
std::atomic<int>* _pcount;
std::function<void(T*)> _del = [](T* rsptr) {
delete rsptr;
};
};
};
最简单的懒汉模式
class Instance
{
public:
static Instance& GetInstance()
{
static Instance instance;
return instance;
}
~Instance()
{}
private:
Instance()
{}
//根据场景设置成员变量。。。
};
-
C++11之前是不安全的,只能用「双重判断 + 锁」的方式进行实现,简单理解构造函数初始化时如果很复杂的可能会被多个线程重入,可能造成初始化的异常问题。
-
双重判断加锁的方式,在线程篇中的生产消费者模型中,进行了详细地讨论,这里只给实现代码和简略说明。
实现代码:
#include<mutex>
class Instance
{
public:
static Instance* GetInstace()
{
if (_thptr == nullptr)
{
std::unique_lock<std::mutex> lg(_mtx);
if (_thptr == nullptr)
{
_thptr = new Instance();
}
}
return _thptr;
}
~Instance()
{
}
//......
private:
Instance()
{}
//锁
static std::mutex _mtx;
//执向单例指针
static Instance* _thptr;
};
//定义:
std::mutex Instance::_mtx;
Instance* Instance::_thptr = nullptr;
- 关键就是获取单例时的判断,因为单例模式只会被初始化一次,因此第一个判断是用来提高线程并行度的,第二个判断保证线程的同步。
C++11版本的线程池
在最后,提及完线程,锁,条件变量之后,我们可以将之前线程文章中用系统接口写的线程池进行升级。
- threadpool.hpp
#include<mutex>
#include<thread>
#include <condition_variable>
#include<vector>
#include<queue>
#include<functional>
#include"Task.hpp"
class Task;
//根据需要应用场景自定义封装一个Task类,然后才能使用此线程池。
//补充说明:Task要内置operator()方法。
class ThreadPool
{
public:
static ThreadPool* GetInstace(int threadnum = 10)
{
if (_thptr == nullptr)
{
std::unique_lock<std::mutex> lg(_mtx);
if (_thptr == nullptr)
{
_thptr = new ThreadPool(threadnum);
}
}
return _thptr;
}
~ThreadPool()
{
for (int i = 0; i < _thread_num; i++)
{
_threads[i].join();
}
}
void handler()
{
while (true)
{
std::unique_lock<std::mutex> lg(_mtx);
while (_tasks.empty())
{
//cout << this_thread::get_id() << endl;
_cv.wait(lg);
}
//否则就获取执行任务
_tasks.front()();
_tasks.pop();
}
}
void start()
{
for (int i = 0; i < _thread_num; i++)
{
_threads[i] = std::thread(bind(&ThreadPool::handler, this));
//进行绑定,对类内函数进行封装。
}
}
void push(const CALTask::Task& task)
{
std::unique_lock<std::mutex> lg(_mtx);
_tasks.push(task);
//唤醒线程进行执行
_cv.notify_one();
}
private:
ThreadPool(int thread_num)
:_thread_num(thread_num)
, _threads(thread_num)
{}
//线程数量
int _thread_num;
//交易场所
std::queue<CALTask::Task> _tasks;
//存放线程
std::vector<std::thread> _threads;
//条件变量
std::condition_variable _cv;
//锁,创建线程时要用,因此设置为静态的。
static std::mutex _mtx;
//线程池的指针
static ThreadPool* _thptr;
};
//定义:
std::mutex ThreadPool::_mtx;
ThreadPool* ThreadPool::_thptr = nullptr;
- Task.hpp
#pragma once
#include<iostream>
#include<string>
#include<functional>
#include<thread>
namespace CALTask
{
enum CAL
{
DIV_ZERO = 1,
MOD_ZERO,
};
char space = ' ';
char newline = '\n';
//解包
std::string Decode(std::string& str)
{
int pos = str.find(newline);
if (pos == std::string::npos) return "";
int len = stoi(str.substr(0, pos));
int totalsize = pos + len + 2;
//如果总的报文的长度大于读取的字符串的长度,说明没有一个完整的报文。
if (totalsize > (int)str.size())
{
return "";
}
//将有效载荷截取出来
std::string actual_load = str.substr(pos + 1, len);
//将完整的报文丢弃,便于下一次进行读取。
str.erase(0, totalsize);
return actual_load;
}
//编码
std::string InCode(const std::string& str)
{
//一个完整的报文:有效载荷的长度 + 换行符 + 有效载荷 + 换行。
std::string text = std::to_string(str.size()) + newline + str + newline;
return text;
}
struct Request
{
Request(int x, int y, char oper)
:_x(x), _y(y), _oper(oper)
{}
Request()
{}
bool Deserialize(std::string& str)
{
std::cout << "-------------------------------" << std::endl;
//首先把字符串的报头和有效载荷进行分离
std::string content = Decode(str);
if (content == "") return false;
//解析字符串:字符 + 空格 + 字符
int left = content.find(space);
int right = content.rfind(space);
if (left + 1 != right - 1)
{
//说明是无效的字符
return false;
}
_x = stoi(content.substr(0, left));
_y = stoi(content.substr(right + 1));
_oper = content[left + 1];
std::cout << "tid: " << std::this_thread::get_id() << std::endl;
std::cout << "解析的字符串:" << _x << _oper << _y << std::endl;
return true;
}
std::string Serialize()
{
std::string package;
//首先对结构体进行编码
//编码格式:字符 + 空格 + 操作符 + 空格 + 字符
package = std::to_string(_x) + space + _oper + space\
+ std::to_string(_y);
//对报文再进行封装
package = InCode(package);
return package;
}
int _x = 0;
int _y = 0;
char _oper = '0';
//给出一个缺省值,避免编译器告警。
};
struct Response
{
Response(int res, int code)
:_res(res), _code(code)
{}
Response()
{}
bool Deserialize(std::string& str)
{
std::string content = Decode(str);
if (content == "") return false;
int pos = content.find(space);
_res = stoi(content.substr(0, pos));
_code = stoi(content.substr(pos + 1));
//for debug:
std::cout << "转换结果:" << _res << " " << _code << std::endl;
std::cout << "-------------------------------" << std::endl;
return true;
}
std::string Serialize()
{
std::string package = std::to_string(_res) + space \
+ std::to_string(_code);
package = InCode(package);
return package;
}
int _res = 0;
int _code = 0;
//同理。
};
struct CalHelper
{
std::string Cal(std::string& str)
{
Request req;
if (req.Deserialize(str) == false) return "";
int x = req._x;
int y = req._y;
char op = req._oper;
int res = 0, code = 0;
switch (op)
{
case '+':
res = x + y;
break;
case '-':
res = x - y;
break;
case '*':
res = x * y;
break;
case '/':
if (!y)
{
code = DIV_ZERO;
break;
}
res = x / y;
break;
case '%':
if (!y)
{
code = MOD_ZERO;
break;
}
res = x % y;
break;
default:
break;
}
return Response(res, code).Serialize();
}
};
//对执行任务进行封装。
using fun_t = std::function<string(std::string&)>;
class Task
{
public:
Task(const string& str, fun_t usr_handler)
:_str(str)
, _usr_handler(usr_handler)
{}
void Service()
{
string str = _usr_handler(_str);
Response res;
res.Deserialize(str);
}
void operator()()
{
Service();
}
private:
fun_t _usr_handler;
string _str;
};
}
- Main.cc
#include<iostream>
#include<thread>
#include<memory>
#include"Task.hpp"
#include"threadpool.hpp"
using namespace std;
CALTask::CalHelper cal;
string opers = "+-*/%";
int main()
{
srand((unsigned)time(nullptr));
shared_ptr<ThreadPool> thptr(ThreadPool::GetInstace());
thptr->start();
while (true)
{
int x = rand() % 10;
int y = rand() % 10;
char op = opers[rand() % opers.size()];
CALTask::fun_t usr_handler = bind(&CALTask::CalHelper::Cal, &cal, std::placeholders::_1);
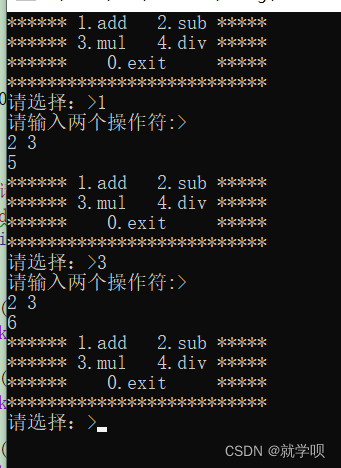
thptr->push(CALTask::Task(CALTask::Request(x,y,op).Serialize(), usr_handler));
Sleep(1000);
}
return 0;
}
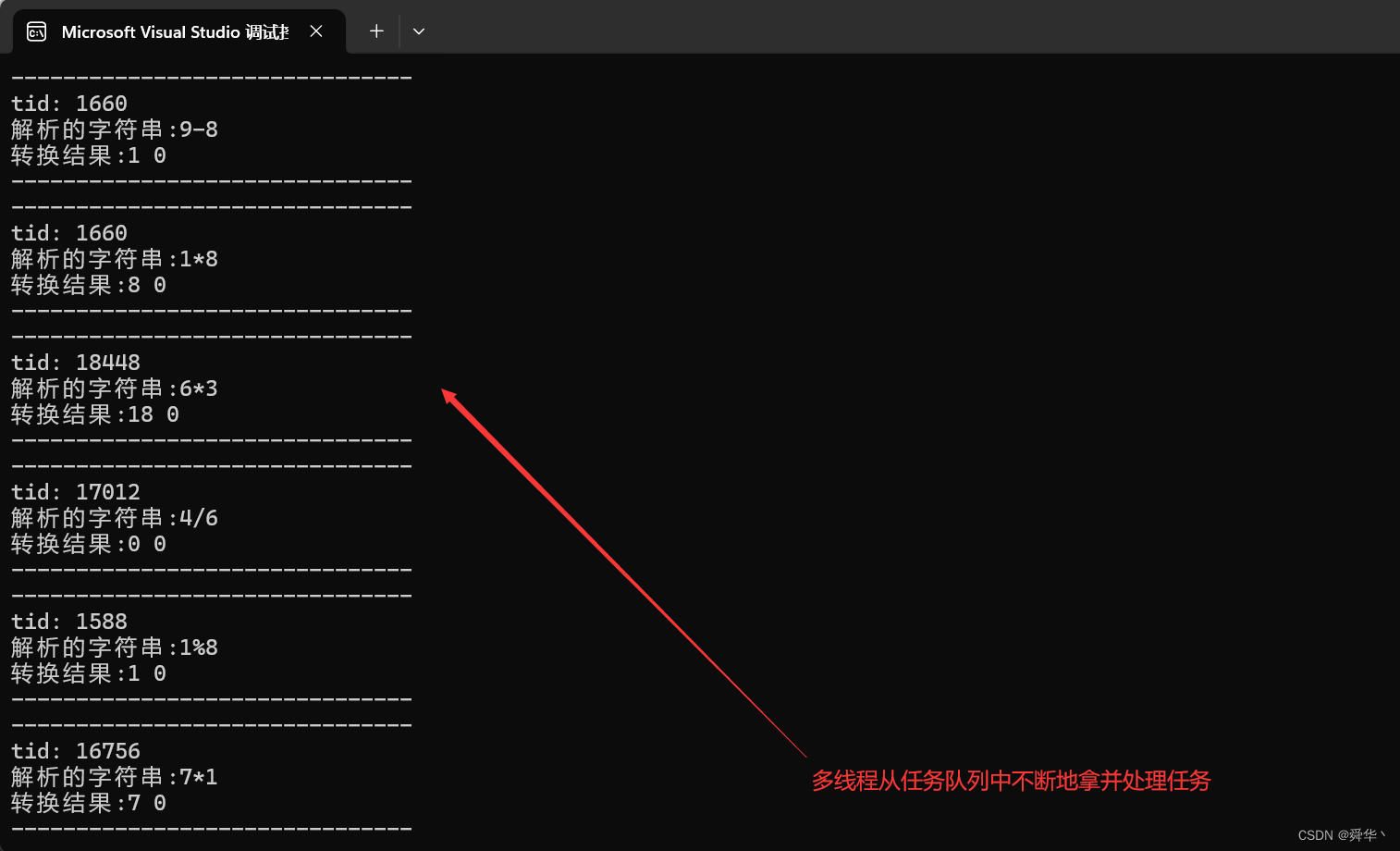
- 运行结果:
尾序
关于线程的分享到这里就结束了,望读者有所收获,我是舜华,一个专注于在技术领域耕耘的博主,期待与你的下一次相遇!

![[网络安全] apt攻击是什么?](https://img-blog.csdnimg.cn/direct/99b9e93268444ee19623fe03fd3d43b9.jpeg#pic_center)